Track Errors First


Observability usually means collecting dashboards, traces, metrics, and logs — or at least, that’s how it’s sold. What’s often missing from that conversation is the most valuable signal of all: errors.
When an exception is raised, your code is telling you: this was not supposed to happen. Not just that something is slow, or that usage is spiking — but that your assumptions, as a programmer, just failed.
That makes an exception — a real, raised error — the single most useful event you can track. If you’re building out observability, whether for the first time or revisiting an existing setup, start with that.
The three pillars of observability
The standard model splits observability into three pillars: logs, metrics, and traces. They’re helpful, but something is missing — and if you only follow this model, you’ll miss it too.
- Logs tell you what the system thought was worth noting.
- Metrics show trends over time: request duration, error rates, cache hit ratios.
- Traces give a sense of flow: what did this request call, and how long did it take?
All of those are useful. But none of them tell you where the code broke. For that, you need proper error tracking.
Signal Over Noise
There’s nothing more direct than a thrown exception. You don’t have to guess whether it’s important. It’s the system saying: this should not have happened, and here’s the line where it went wrong.
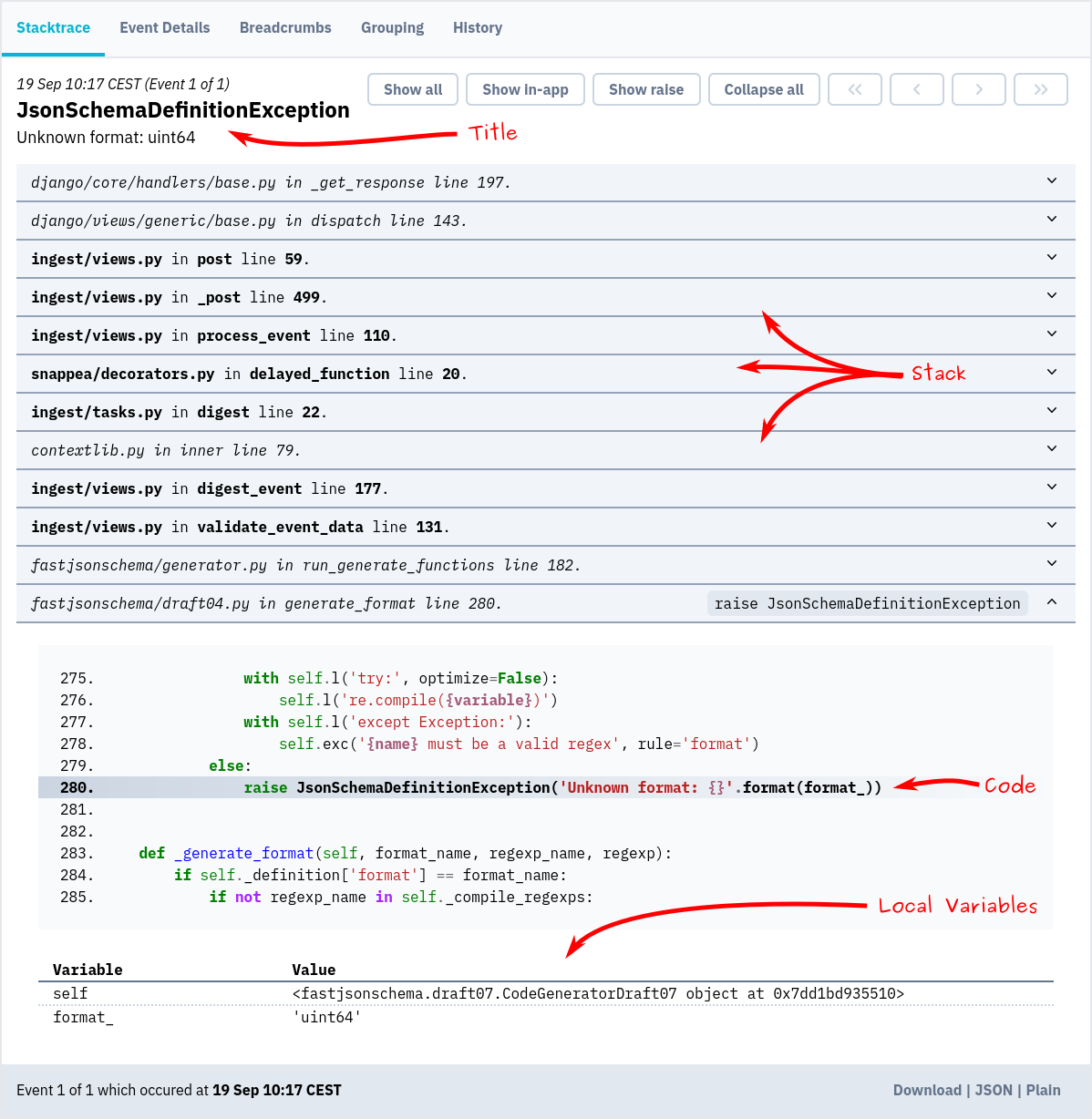
And because exceptions are so rare – so high-signal – it’s worth going deep when they happen. You want to capture:
- The full stacktrace — readable, with line numbers and source references
- Local variables — so you know what was actually passed in
- Request data — like URL paths, headers, or session info
- User context — who was affected, what were they doing?
You can’t get this from a metric. And you usually don’t get it from a log line unless you’ve done a lot of extra work.
So instead of collecting a little information about everything that works — one trace here, one log line there — you’re better off collecting as much context as possible at the moment your system breaks.
As one developer put it: “One exception is worth a thousand logs.”
Missing from the Diagram
The canonical “three pillars” of observability are logs, metrics, and traces. But error tracking isn’t even mentioned.
If you believe exceptions are your highest-signal events — and you probably should — then this model doesn’t just feel incomplete. It’s actively misleading.
It reflects what’s easy to generalize, easy to collect, and easy to sell — not necessarily what’s most useful when your code breaks.

Technically Covered
In most observability platforms, errors are not missing — just abstracted. They show up in logs, get counted in metrics, or appear as failed spans in traces. Some platforms file them under generic “events,” alongside cache misses, deployments, and GC pauses.
This flattening makes implementation easier. Everything becomes a stream of telemetry — uniform, processable, and easy to route.
But that abstraction comes at a cost. An exception isn’t just another event. It’s your code telling you it failed, in a specific place, with a specific context. If the system treats that like just another row in a data pipeline, you’ll likely get the minimum: a message string, maybe a timestamp, maybe a partial trace.
Error tracking requires collecting more. Stack traces, local variables, request metadata, user context — details that rarely make it into standard logs or metric counters.
So yes, errors are technically covered. But they’re not treated as meaningful failures. Just another data point, in a sea of unrelated ones.
You’re (probably) not Google
You’re probably not Google. And even if you are, errors should come first — APM second. Exceptions give you the clearest, most actionable signal when something breaks. You want full context, not a red dot on a dashboard.
Plenty of APM tools claim to track errors — but often that just means counting them. You get a spike on a chart, maybe a summary, rarely the full story. If exceptions are your highest-signal events, that shouldn’t be an afterthought.
And watch out even with dedicated error tracking tools. Some of them started strong, fast, focused, developer-first, but have since drifted into full observability platforms. Dashboards got added, then tracing, then metrics pipelines. More tabs, more noise, more clicks.
So take a moment to check: Are errors still first-class in your stack? Or just another checkbox on a sales sheet?
Not your Neutral Observer
So who’s your friendly author? I’m Klaas, the founder of Bugsink: an error tracking tool.
So yes, I have a stake in this – but not by accident.
I built a tool around this belief, not the other way around. And I think the current ecosystem, with its emphasis on full-stack APM suites and dashboard-driven ops, tends to push errors to the background. That’s a mistake.
Track errors first.